
正規表現は文字列の検索や置換を行うための強力で便利なツールです。基本をマスターすれば開発から日常の事務作業までさまざまな場面でラクをできる魔法の道具ですが、見た目がちょっと分かりづらいので、避けている方もいるのではないでしょうか? 筆者の個人的観測ですが、とりわけフロントエンドのエンジニアには正規表現に苦手意識を感じている方が多いようです。
この記事では正規表現の基本と、正規表現がどこで使えてどれだけ便利になるのかを紹介します。
正規表現の基本:正規表現ってそもそも何?
正規表現(regular expression)は、ごく簡単にいえば「さまざまな文字列のバリエーションをひとつの文字列で表現したもの」です。たとえば、郵便番号の7桁の数字には(実際に使われていないものも含めれば)一千万通りのバリエーションがありますが、正規表現を使えば次のようにひとつの文字列で表現できます。
▼「7桁の数字」の正規表現:先頭(^)から末尾($)までの間に7個の数字が並んでいる文字列
^[0-9]{7}$
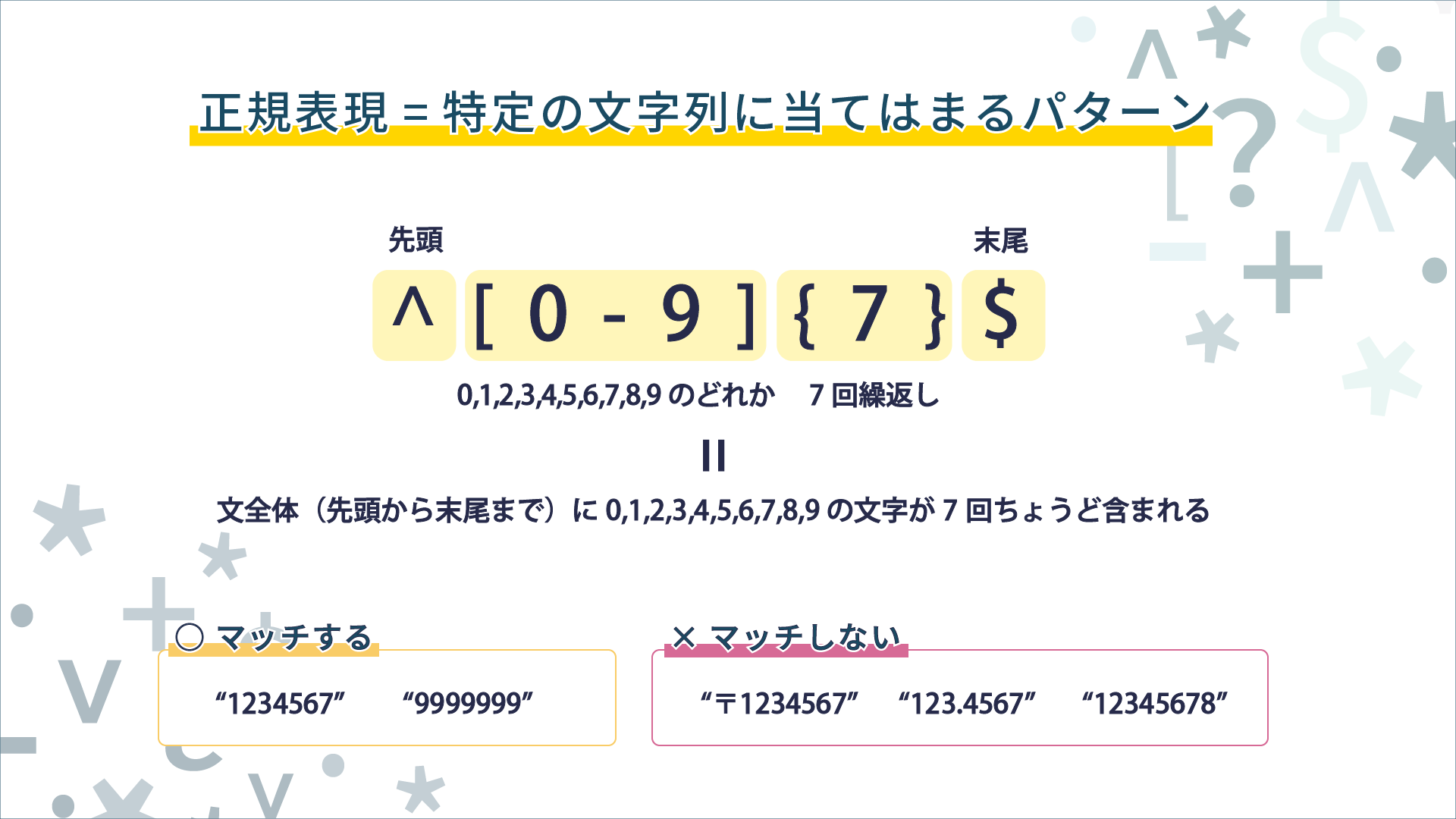
文字列の先頭を示す^と末尾を示す$の間に数字(0〜9)が7個並んでいる、という正規表現です。郵便番号なので間に「-」を入れてもいいことにしたい場合は次のように表現できます。
▼3桁目と4桁目の間に「-」があっても良い(なくても良い)7桁の数字
^[0-9]{3}-?[0-9]{4}$
この正規表現を使って、入力した文字が郵便番号かどうかチェックするJavaScriptは次のようになります。
const postalCode = prompt('7桁の郵便番号を入力してください');
if (!postalCode.match(/^[0-9]{3}-?[0-9]{4}$/)) {
alert('郵便番号は7桁(xxx-xxxxまたはxxxxxxx)で入力してください');
}
実はものすごく長い正規表現の歴史
現在でもさまざまな場所で使われる正規表現ですが、その歴史はプログラミング言語の登場以前まで遡ると言われます。元々は数学や言語学の分野で用いられていた理論をコンピューターでの作業に利用したもので、半世紀以上の歴史があります。

1988年にプログラミング言語のPerlに今のベースとなる拡張正規表現が導入されました。JavaScriptをはじめとした今日メジャーなプログラミング言語の正規表現はおおむね、このPerlの正規表現をお手本として実装されています(細部の機能は言語や処理系で異なります)。JavaScriptの誕生が1995年ですから、それよりも大分古いですね。まだ生まれていなかった方も多いのではないでしょうか?
変化の早いプログラミングの世界の中では、正規表現は古参で枯れた(成熟した)技術です。基本だけでも覚えておけば「一生モノ」のスキルになるかもしれません。
HTML/JavaScriptで正規表現を使う
ここからはエンジニアの開発や業務で実装に正規表現を使えるケースを見ていきましょう。まずは一番馴染み深いHTMLとJavaScriptからです。
input要素のバリデーションに正規表現を使う
HTMLのinput要素は入力内容が適切かチェックするバリデーションの機能を標準で備えています。バリデーションを有効にするにはpattern属性に正規表現を指定します。
次の例は生年月日を20030405のような8桁の数字か、2003/4/5のようなスラッシュ区切りの文字列で入力させるフォームです。
<form>
<label for="birthday">生年月日</label>
<input
type="text"
id="birthday"
required
title="生年月日はyyyymmddまたはyyyy/m/dで入力してください"
placeholder="yyyymmddまたはyyyy/m/dで入力"
pattern="\d{8}|\d{4}/\d{1,2}/\d{1,2}"
/>
<button type="submit">送信</button>
</form>
使い方は簡単で、pattern属性に期待する文字列パターンの正規表現を指定するだけです。なお、input要素のpattern属性は常に入力文字列全体へのマッチをチェックするので、先頭・末尾にマッチさせる^や$を入力する必要はありません。(逆に「.jpgで終わる文字列にマッチさせたい」といった場合は\.jpgではなく.*\.jpgのように明示する必要があります)
正規表現を上手に使えば、少々込み入ったバリデーションもJavaScriptなしで実装できます。より実践的な利用方法は以前の記事『CSS疑似クラスを活用した、モダンでインタラクティブなフォームの作り方』もご覧ください。
JavaScriptの正規表現で文字列を自在に操作
記事の最初に紹介したように、JavaScriptには正規表現が標準で組み込まれているので、文字列の検索が簡単に行えます。
▼ 正規表現を使った基本的な検索(マッチ)の例
const text = "最寄駅は東京メトロ東西線西葛西駅です";
text.search(/東|西/);
// → 4
text.match(/東|西/g);
// → ['東', '東', '西', '西', '西']
/東|西/.test(text);
// → true
/東|西/.exec(text);
// → ['東', index: 4, input: '最寄駅は東京メトロ東西線西葛西駅です', groups: undefined]
実は正規表現を使えるsplitとreplace関数
文字列の分割を行うsplit関数とreplace関数では、実は引数に正規表現を使うことができます。次の例は文字列をカンマ区切りで分割する際に、カンマの前後のスペースを取り除く例です。
const text = "apple, orange , banana";
const fruitsList = text.split(/\s*,\s*/)
// → ['apple', 'orange', 'banana']
replace関数やreplaceAll関数も引数に正規表現を使うことで応用的な使い方ができます。次の例はCSSのプロパティー名で使われるケバブケースの文字列をJavaScriptで一般的なキャメルケースに変換する処理です。
const cssProp = "border-top-left-radius";
const jsProp = cssProp.replaceAll(/-([a-z])/g, match => match[1].toUpperCase());
// → borderTopLeftRadius
また、replace関数は検索条件に指定した正規表現内のキャプチャ(カッコ()でくくられた部分)を使って文字列の置換や組み替えを自由に行うこともできます。次の例ではy年m月d日形式で表現された日付を米国式にm/d/y形式へと変換します。
const dayJp = "2022年10月3日";
// 米国式は月/日/年
const dayUs = dayJp.replace(/^(\d{4})年(\d{1,2})月(\d{1,2})日$/, "$2/$3/$1");
// → 10/3/2022
開発だけじゃない! 正規表現が便利なアプリ4選
正規表現が活用できるのはプログラミングの中だけではありません。実は普段使っているアプリケーションやサービスでも、正規表現に対応しているものがたくさんあります。
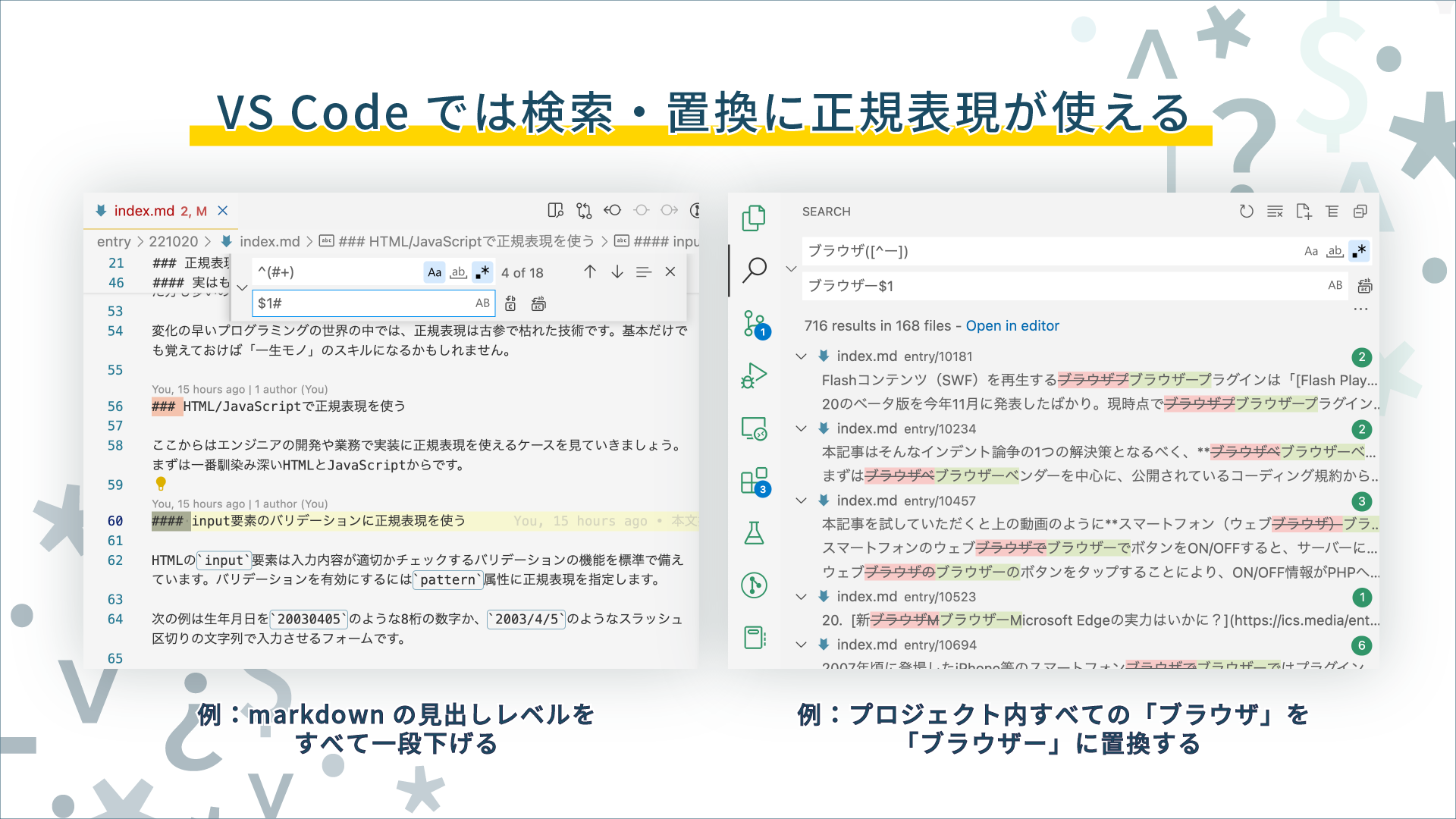
Visual Studio Codeや各種IDE・テキストエディター
Visual Studio Code(VS Code)をはじめとして、IDEやエディターの多くではテキストの検索・置換に正規表現が利用できます。
VS Codeの場合、検索ボックス右側の.*で正規表現のON/OFFを切り替えられます。また、置換の場合、JavaScriptのreplace関数と同様に$1,$2…を使ってヒットした文字列を利用した置き換えを行うことも可能です。
Figma
次はFigmaです。Figmaでは複数のレイヤーやオブジェクトを選択してコマンド+R(WindowsではControl+R)で一括リネームを行えますが、この際に正規表現が利用できます。
たとえば、名前がxxx_image,xxx_img,xxxImgのようにバラバラになってしまっているものをxxx_imageに統一したい場合、すべての要素を選択してリネームダイアログを開き、次のように指定します:
- Match:
(_image|_img|Img)$ - Rename to:
_image
また、Figmaでは独自の拡張として$nや$nnといったパターンで連番を付与できます。次の例はこの機能を使って、既存のレイヤー名のナンバリングを捨てて新たに3桁の連番をふり直すものです:
- Match:
^[0-9]+_ - Rename to:
$nnn_
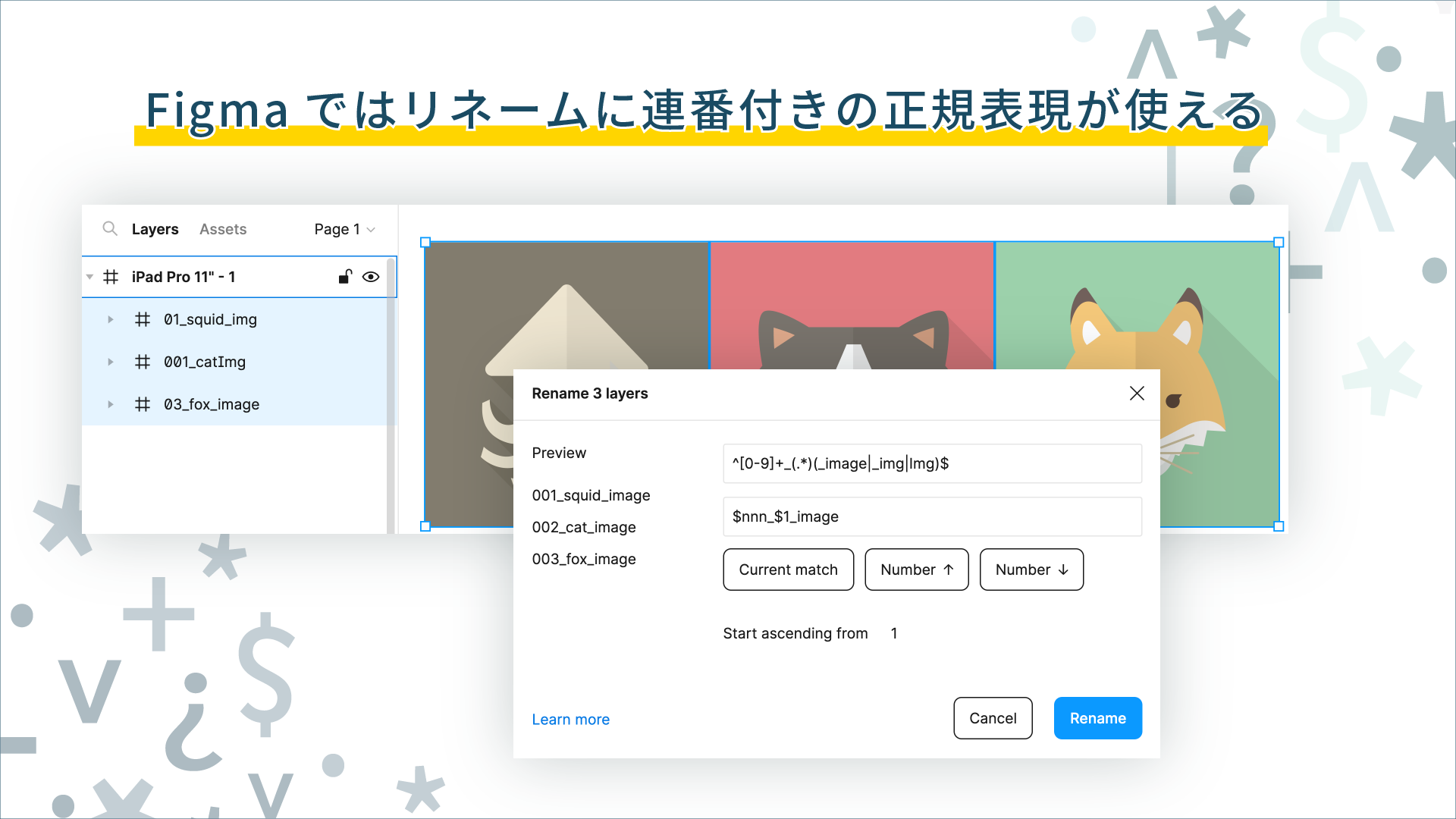
デザインファイルでの命名が整っていると後工程でのトラブルも減って実装の負担も下がります。うまく活用してスマートにリネームをしたいですね。
Googleドキュメント・Googleスプレッドシート
GoogleドキュメントやGoogleスプレッドシートでも、検索・置換に正規表現が利用できます。とくにGoogleスプレッドシートでは通常の検索・置換に加えて、以下のワークシート関数でも正規表現を利用できます。
REGEXMATCH(テキスト, 正規表現)…… テキストが正規表現にマッチするかチェックするREGEXEXTRACT(テキスト, 正規表現)…… テキストの正規表現にマッチする部分を抜き出すREGEXREPLACE(テキスト, 正規表現, 置換)…… テキストの正規表現にマッチする部分を置換する
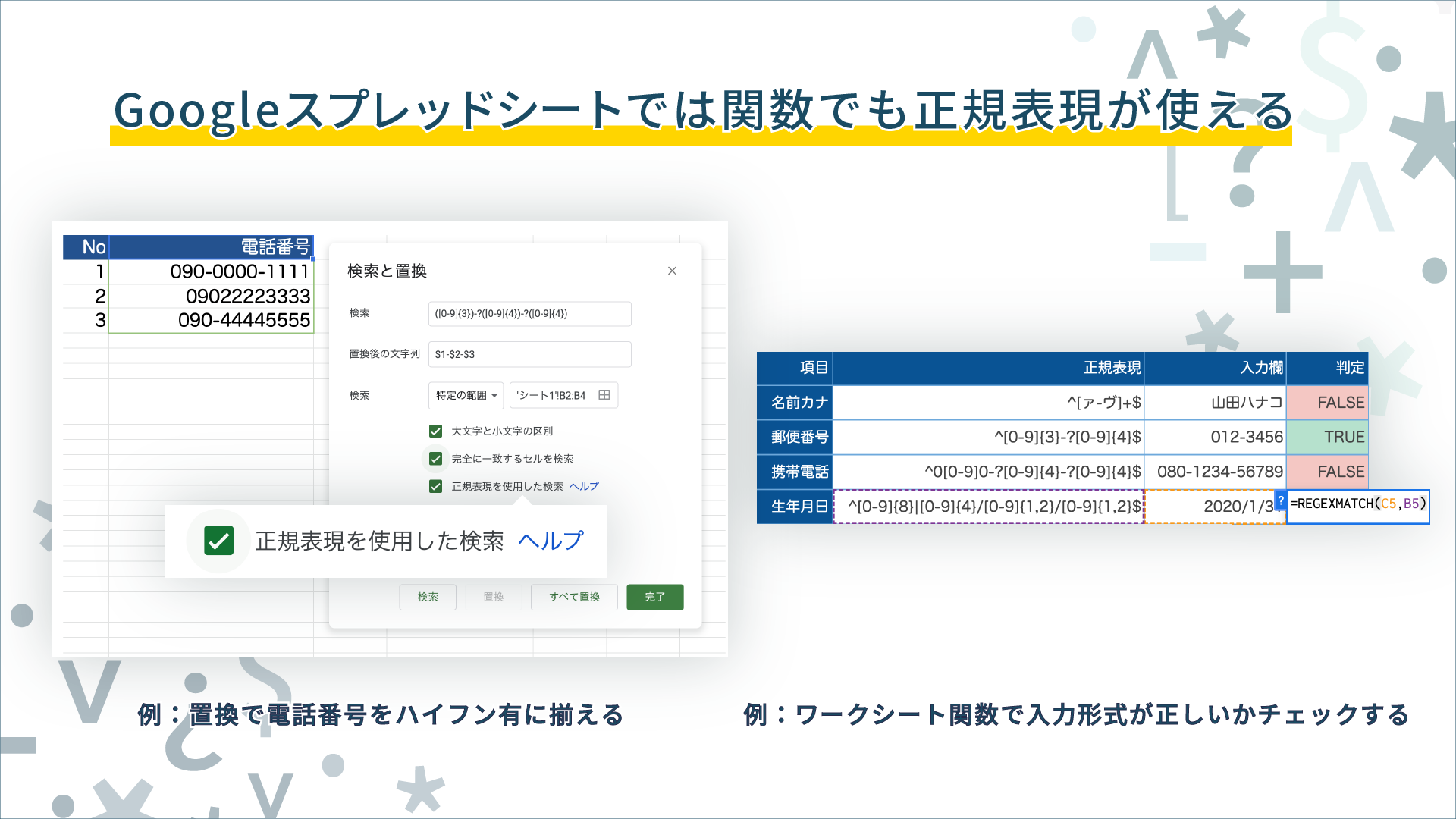
HTMLのフォームと同様に入力値のバリデーションに使ったり、表記揺れのある入力データを整形したりする際に力を発揮するはずです。ぜひ覚えておきましょう。
コマンドライン
コマンドラインではさまざまな場所で正規表現が利用できますが、ここではひとつだけsedコマンドを紹介します。sedはmacOSを含むLinux・Unix環境であれば特別なセットアップなしで利用できる標準的なコマンドです。
sedコマンドにはいくつかの機能がありますが、以下のように書くとテキストファイルを正規表現を使って置換できます。
# マッチしたすべての文字列を置換して別のファイルに保存する
sed -e 's/正規表現/置換文字列/g' 入力ファイル名 > 出力ファイル名
# 同じファイルに上書き保存する場合はiオプションを使う
sed -i -e 's/正規表現/置換文字列/g' ファイル名
次の例ではindex.htmlに含まれる"http:"を"https:"に置換しています:
sed -i -e 's/http:/https:/g' index.html
日常の作業でsedコマンドを使うことは稀ですが、エンジニアにとってはビルドコマンドやCIの構築で力を発揮します。ビルド前後のファイルやログ等のテキストをちょっと検索・置換したいケースは多々ありますが、それだけのためにNode.js用のプログラムを書くのは面倒です。sedのようなコマンドを知っていれば、簡単な置換処理なら1行で実行できる上、処理も高速です。コマンドラインは苦手という方でも、いざという時のために存在だけは覚えておいても損はないでしょう。
使い過ぎに注意!? 正規表現のデメリットとリスク
正規表現は強力なツールですが、正しく使わないと予期しない事故に巻き込まれることもあります。記事の最後に正規表現を使う際に認識しておきたいデメリットとリスクを紹介します。
1. 使いすぎると可読性や保守性が下がる
強力なツールを手にするとそれを使いたくなるものですが、とくに正規表現では注意が必要です。たとえば、入力ファイル名の拡張子が"jpg"であることをチェックしようとして次のように書いたとします。
▼ 末尾が".jpg"であることを正規表現で確認する関数(間違った例)
const isValidJpgFileName = (name) => {
return /.jpg$/.test(name);
};
この関数は正規表現として\.jpg$と書くべきところを.jpg$としてしまっているため、たとえば"photo.notjpg"のような誤ったファイル名にもマッチしてしまいます。(.は任意の1文字にマッチする正規表現です)
このようなバグはレビューやテストでも見落とされがちです。正規表現を使わずに済むのであれば使わない方が分かりやすいケースも多いでしょう。
▼ 末尾が".jpg"であることを正規表現を使わずに確認する関数
const isValidJpgFileName = (name) => {
return name.endsWith(".jpg");
};
2. 不必要(過剰)なチェックはユーザビリティを下げることもある
フォームのメールアドレスや電話番号のバリデーションに正規表現を使うことは一般的ですが、こちらも使い過ぎには注意が必要です。
下の正規表現は『Email Address Regular Expression That 99.99% Works.』から引用した「正確な」メールアドレスの正規表現です。
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
この正規表現はRFCに照らせば(おそらくは)正確なものと思われますが、実際にこれを使うべきかは疑問です。たとえば有名なところでは、ドコモのメールアドレスであるdocomo..ab1234yz@docomo.ne.jpはこの正規表現ではマッチしません。つまり、この正規表現をコピペしてフォームのバリデーションを行うと、フォームを送信できないユーザーが出てきてしまうことになります(ドコモではこのようなメールアドレスの新規発行はできなくなりましたが、他にも同様の例はあると思われます)。
いくら厳しいチェックを行ったところで、入力されたメールアドレスが存在して送受信可能なものかどうかまでは正規表現では分かりません。バックエンドのDBや連携している外部サービス側の指定がない限り、過剰な(または理解できない)バリデーションを行うべきではないでしょう。
3. 正規表現でサービス停止!? セキュリティリスクになることがある
不用意な正規表現の利用はセキュリティのリスクとなることもあります。フォームのバリデーションのようなクライアントサイドのJavaScriptではあまり問題はありませんが、サーバー側で利用する場合「ReDoS攻撃」と呼ばれる攻撃に利用される可能性があります。
次の正規表現はReDoS攻撃に利用されうる危険な正規表現の例です:
/^(([0-9])+)+$/
この正規表現を長さが25文字の文字列にマッチさせたのが下の例です。手元の環境では216ミリ秒かかっています。
console.time(); // 測定開始
console.log("012345678901234567890123456a".match(/^(([0-9])+)+$/));
console.timeEnd(); // 測定終了
// null
// default: 216.307861328125 ms
文字列をあと5文字長くしてみましょう。処理時間が一気に20倍になりました。この先は1,2文字増やすだけで途方もない時間がかかるようになってしまいます。(実行時間は環境で異なるので、お手元で試す場合はご注意ください)
console.time()
console.log("01234567890123456789012345678a".match(/^(([0-9])+)+$/))
console.timeEnd()
// null
// default: 5609.10595703125 ms
この脆弱性は正規表現の仕様によるものなので簡単には解決できません。ブラウザー上であれば最悪でもブラウザーが固まるだけで済みますが、サーバーサイドでは処理が詰まってサービスが止まってしまったり、クラウド環境であれば課金額が跳ね上がる可能性もあります。
危険な正規表現はredos-checkerのようなツールでもある程度は検証可能です。また、SQLインジェクションやXSSの対策と同様、正規表現についてもユーザーからの入力文字列をそのまま埋め込んで使ってはいけません。
普通のウェブ開発ではそこまで怖がる必要はありませんが、使い方や使う場所によってはリスクとなり得ることは理解しておきましょう。
まとめ:正規表現を程よく使ってラクしよう
正規表現は深く理解しようとするととても大変なものですが「普通の検索にちょっと機能を足しただけ」のものとして使う分には決して難しくありません。基本的な使い方だけ一度覚えれば、開発だけでないさまざまな仕事をちょっと効率的にこなせるでしょう。この記事では正規表現の書き方自体はあまり説明しなかったので、興味のある方は下記のリストも参考に学んでみてください。
- 正規表現の基本的な書き方の網羅的な解説:とほほの正規表現入門
- JavaScriptでの正規表現の使い方:MDN 正規表現
- 正規表現をチェックできるウェブツール:WWWクリエイターズ 正規表現チェッカー

